Skin Cancer Segmentation and Classification
Skin Cancer Segmentation and Classification with Improved Deep Convolutional Neural Network
Introduction
In the last few years, Deep Learning (DL) has been showing superior performance in different modalities of bio-medical image analysis. Several DL architectures have been proposed for classification, segmentation, and detection tasks in medical imaging and computational pathology. We propose a new DL architecture, the NABLA-N network (∇N-Net), with better feature fusion techniques in decoding units for dermoscopic image segmentation tasks. The ∇N-Net has several advances for segmentation tasks. First, this model ensures better feature representation for semantic segmentation with a combination of low to high-level feature maps. Second, this network shows better quantitative and qualitative results with the same or fewer network parameters compared to other methods. In addition, the Inception Recurrent Residual Convolutional Neural Network (IRRCNN) model is used for skin cancer classification. The proposed ∇N-Net network and IRRCNN models are evaluated for skin cancer segmentation and classification on the benchmark datasets from the International Skin Imaging Collaboration 2018 (ISIC-2018). The experimental results show superior performance on segmentation tasks compared to the Recurrent Residual U-Net (R2U-Net). The classification model shows around 87% testing accuracy for dermoscopic skin cancer classification on ISIC2018 dataset.
Goals/Objectives
- A new segmentation model, the NABLA-N network (∇N-Net), is proposed and applied to a skin cancer segmentation task on the ISIC 2018 dataset.
- The impact of different fusion approaches in encoding and decoding units are investigated.
- The impact of transfer learning (TL) from ISIC-2017 to ISIC-2018 is evaluated for the segmentation task.
- An IRRCNN model is applied for skin cancer classification on the ISIC 2018 dermoscopic image dataset.
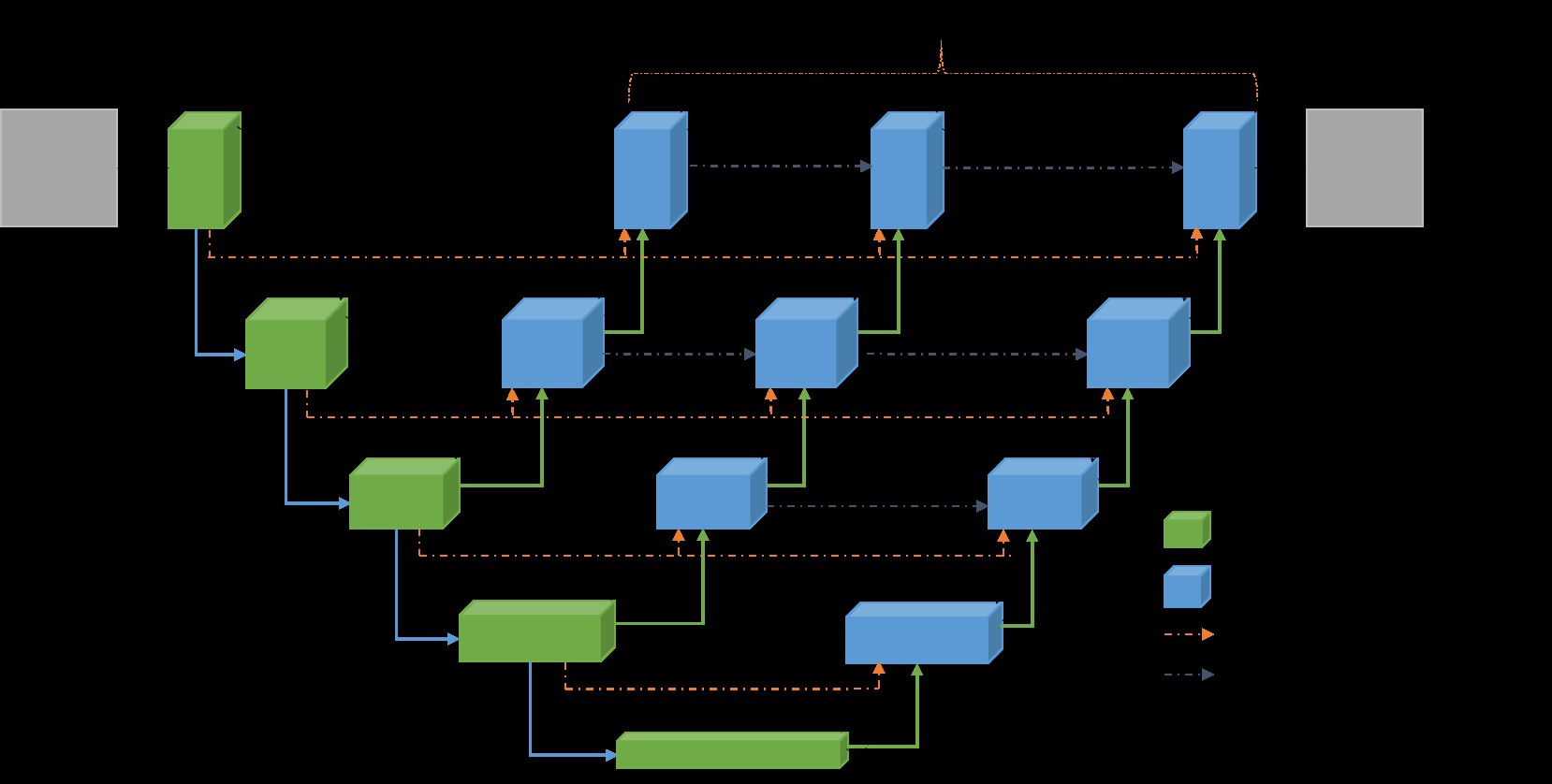 Figure 1. ∇3-Net CNN model semantic bio-medical image segmentation consists of encoding and decoding units. Three encoded feature spaces are used.
Figure 1. ∇3-Net CNN model semantic bio-medical image segmentation consists of encoding and decoding units. Three encoded feature spaces are used.
Results
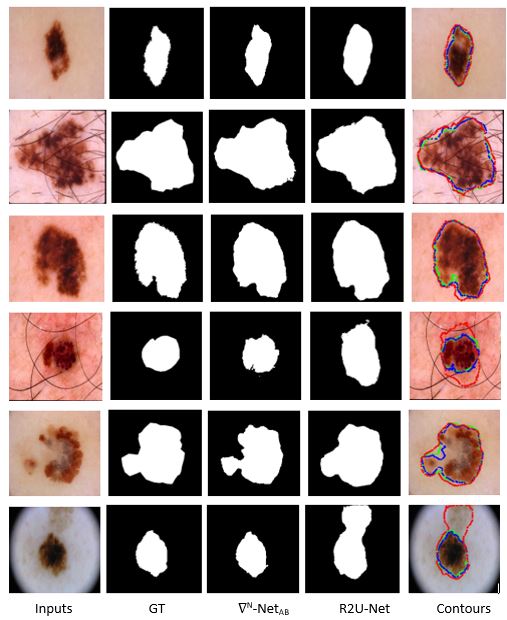 Figure 2. The first column shows the inputs, the second column shows the Ground Truth (GT), the third column shows the outputs from ∇N-NetAB, fourth columns show the outputs for R2U-Net, and the fifth column shows the results with respective contours for GT, R2U-Net, and ∇N-Net models where green color represents the GT, blue color for ∇2-NetAB, and red color shows contour for R2U-Net model.
Figure 2. The first column shows the inputs, the second column shows the Ground Truth (GT), the third column shows the outputs from ∇N-NetAB, fourth columns show the outputs for R2U-Net, and the fifth column shows the results with respective contours for GT, R2U-Net, and ∇N-Net models where green color represents the GT, blue color for ∇2-NetAB, and red color shows contour for R2U-Net model.
Paper link: https://arxiv.org/abs/1904.11126