Recurrent Residual U-Net
Recurrent Residual U-Net (R2U-Net) for Medical Image Segmentation
IntroductionDeep learning (DL) based semantic segmentation methods have been providing state-of-the-art performance in the last few years. More specifically, these techniques have been successfully applied to medical image classification, segmentation, and detection tasks. One deep learning technique, U-Net, has become one of the most popular for these applications. We propose a Recurrent U-Net as well as a Recurrent Residual U-Net model, which are named RU-Net and R2U-Net respectively. The proposed models utilize the power of U-Net, Residual Networks, and Recurrent Convolutional Neural Networks (RCNNs). There are several advantages of these proposed architectures for segmentation tasks. First, a residual unit helps when training deep architectures. Second, feature accumulation with recurrent residual convolutional layers ensures better feature representation for segmentation tasks. Third, it allows us to design better U-Net architectures with the same number of network parameters with better performance for medical image segmentation. The proposed models are tested on three benchmark datasets such as blood vessel segmentation in retinal images, skin cancer segmentation, and lung lesion segmentation. The experimental results show superior performance on segmentation tasks compared to equivalent models including a variant of a fully connected convolutional neural network (FCN) called SegNet, U-Net, and the residual U-Net (ResU-Net).
Goals/Objectives
- Two new models called RU-Net and R2U-Net are introduced for medical image segmentation.
- Experiments are conducted on three different modalities of medical imaging including retinal blood vessel segmentation, skin cancer segmentation, and lung segmentation.
- Performance evaluation of the proposed models is conducted for the patch-based method for retinal blood vessel segmentation tasks and the end-to-end image-based approach for skin lesion and lung segmentation tasks.
- Comparison against recently proposed state-of-the-art methods shows superior performance against equivalent models with the same number of network parameters.
- Empirical evaluation of the robustness of the proposed R2U-Net model against SegNet and U-Net based on the trade-off between the number of training samples and performance during the training, validation, and testing phases.
Methodology
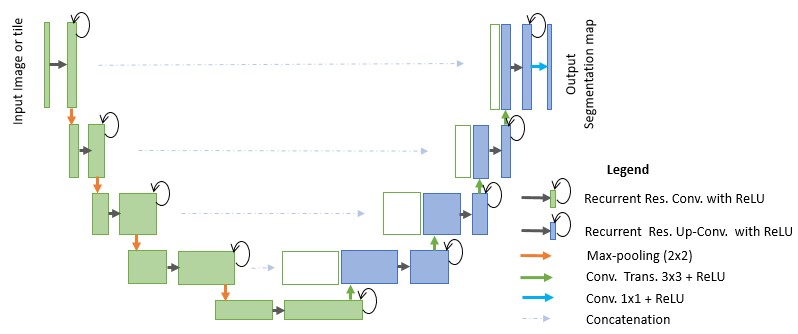 Figure 1. The RU-Net architecture with convolutional encoding and decoding units using recurrent convolutional layers (RCL), which is based on a U-Net architecture. The residual units are used with the RCL for R2U-Net architectures.
Figure 1. The RU-Net architecture with convolutional encoding and decoding units using recurrent convolutional layers (RCL), which is based on a U-Net architecture. The residual units are used with the RCL for R2U-Net architectures.
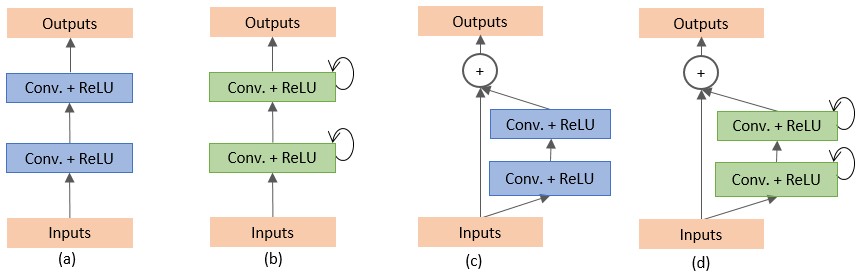 Figure 2. Different variants of the convolutional and recurrent convolutional units including (a) the forward convolutional unit, (b) the recurrent convolutional block (c) the residual convolutional unit, and (d) the Recurrent Residual Convolutional Unit (RRCU).
Figure 2. Different variants of the convolutional and recurrent convolutional units including (a) the forward convolutional unit, (b) the recurrent convolutional block (c) the residual convolutional unit, and (d) the Recurrent Residual Convolutional Unit (RRCU).
Results
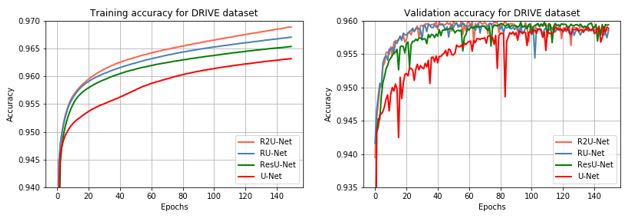 Figure 3. Training and validation accuracy of the proposed RU-Net and R2U-Net models compared to the ResU-Net and U-Net models for blood vessel segmentation task. Training accuracy is on the left and validation is on the right.
Figure 3. Training and validation accuracy of the proposed RU-Net and R2U-Net models compared to the ResU-Net and U-Net models for blood vessel segmentation task. Training accuracy is on the left and validation is on the right.
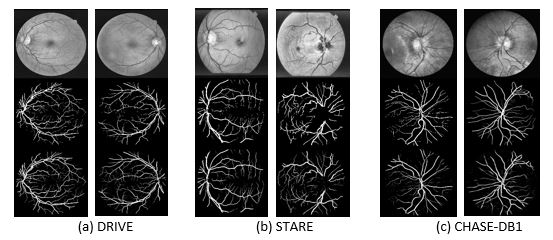 Figure 4. Experimental outputs for three different datasets for retinal blood vessel segmentation using R2UNet. The first row shows input images in grayscale, the second row shows the ground truth, and the third row shows the experimental outputs. The images correspond to the (a) DRIVE, (b) STARE, and (c) CHASE_DB1 datasets.
Figure 4. Experimental outputs for three different datasets for retinal blood vessel segmentation using R2UNet. The first row shows input images in grayscale, the second row shows the ground truth, and the third row shows the experimental outputs. The images correspond to the (a) DRIVE, (b) STARE, and (c) CHASE_DB1 datasets.  Figure 5. Illustration of qualitative assessment of the proposed R2U-Net for the skin cancer segmentation task. The first column shows the input sample, the second column shows ground truth, the third column shows the outputs from the SegNet model, the fourth column shows the outputs from the U-Net model, and the fifth column shows the results of the proposed R2U-Net model.
Figure 5. Illustration of qualitative assessment of the proposed R2U-Net for the skin cancer segmentation task. The first column shows the input sample, the second column shows ground truth, the third column shows the outputs from the SegNet model, the fourth column shows the outputs from the U-Net model, and the fifth column shows the results of the proposed R2U-Net model.
 Fig. 6 The experimental results for lung segmentation where the first column shows the inputs, the second column shows the ground truth, the third column shows the outputs of SegNet, the fourth column for the outputs of U-Net, and a fifth column for the outputs of R2U-Net.
Fig. 6 The experimental results for lung segmentation where the first column shows the inputs, the second column shows the ground truth, the third column shows the outputs of SegNet, the fourth column for the outputs of U-Net, and a fifth column for the outputs of R2U-Net.
Paper link: https://www.ncbi.nlm.nih.gov/pubmed/30944843